


Qu’est-ce qu’un ETL ?
L’ETL, Extract Transform Load, est un middleware, qui fait transiter la donnée d’un point A vers un point B à intervalles définis. Ces trois verbes résument les trois phases, ou processus, de chaque flux de données.
Une première phase d’extraction de la donnée, pouvant provenir de n’importe quelle source, base de données, FTP, Amazon S3, Dropbox, Google Drive, dossier Linux etc…
La donnée, dépendamment de la source, peut également être extraite sous n’importe quel format, SQL, JSON, XML, EDI, positionnel, Excel…
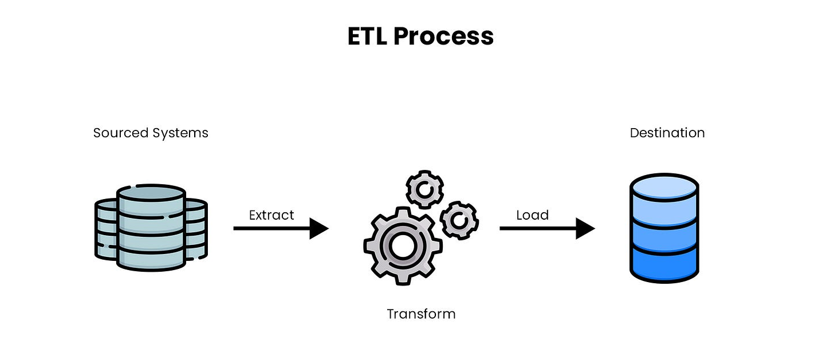
Une seconde phase de transformation pour appliquer les règles de gestion, nettoyer la donnée, filtrer la donnée non pertinente etc…
Une troisième phase d’intégration dans une cible, au même titre que l’extraction, sous n’importe quel format et source.
L’avantage de l’ETL c’est de pouvoir être flexible et de couvrir les cas les plus communs grâce à la diversité des sources et formats d’entrée/sortie.
L’inconvénient de l’ETL c’est de devenir une « boîte noire » difficile à maintenir ou évoluer.
Qu’est-ce qu’un ESB ?
L’ESB, Enterprise Service Bus, permet de faire communiquer des applications, au sein d’un même système d’information, qui n’ont pas été conçus pour fonctionner ensemble.
Cette problématique est résolue en créant un bus qui va permettre d’écouter et de transmettre la donnée d’une application A vers une application B, et d’une application B vers une application A.
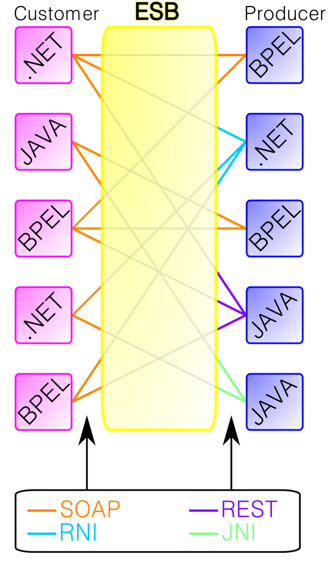
De cette façon, si le système d’information client grandit, dû au rachat d’un concurrent ou à l’ajout d’un nouvel outil pour les équipes métier par exemple, la nouvelle application devra simplement être « connecté » à l’ESB pour être intégré au système déjà en place.
L’avantage c’est d’éviter la refonte d’un système d’information à chaque intégration d’un nouveau logiciel ou une nouvelle application.
L’inconvénient c’est d’avoir des applications qui doivent être en mesure d’échanger de l’information, en temps réel, notamment sous un format SOAP ou REST.
Comment distinguer un ETL d’un ESB ?
Récupération de la donnée
La principale différence entre l’ETL et l’ESB concerne la manière dont la donnée est récupérée.
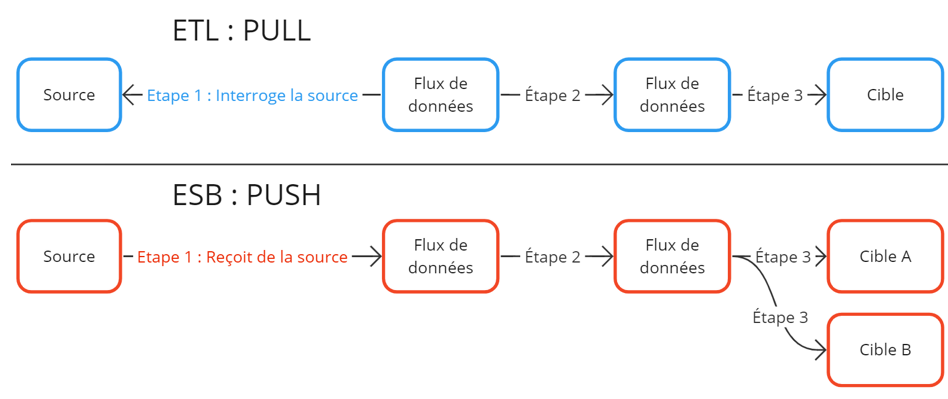
L’ETL fonctionne en « pull», le flux de données est un flux planifié, qui va s’exécuter à la demande et aller chercher (=pull) la donnée dans une source définie pour faire un travail attendu.
Le flux ETL est un flux actif qui va chercher la donnée.
L’ESB fonctionne en « push », le flux est dit « évènementiel », et va s’exécuter dès lors qu’une donnée est reçue depuis une application source.
A la réception de celle-ci, le bus distribue (=push) aux applications cibles l’informations reçue via un système de « publisher/subscriber ».
Le flux ESB est un flux passif qui fait transiter la donnée.
Délai d’intégration de la donnée
La seconde différence, liée à la première, est le temps d’intégration des informations.
L’ETL fonctionnant en mode planifié, la donnée sera intégrée au moment où le flux planifié aura terminé son traitement.
Selon le déclencheur, la donnée sera synchronisée à la fin de l’exécution.
Ces déclencheurs peuvent être mis en place toutes les heures, tous les jours, à intervalles réguliers etc…
L’ESB est quant à lui évènementiel. Il va recevoir la donnée dans le bus dès lors qu’elle est créée ou modifiée dans l’application source.
A sa réception dans le bus, la donnée est expédiée vers les cibles en temps réel après des étapes simples de transformations et via un système de « publisher/subscriber ».
L’intégration, à la différence de l’ETL, se fait en temps réel.
Volumétrie
La troisième différence, liée à la seconde, concerne la volumétrie.
L’ETL est conçu pour traiter de larges volumétries à des instants programmés dans la journée, donc à faible intensité.
Exemple : un flux se lance une fois par jour, va lire une table de dix mille lignes en base de données.
Dans ce cas de figure il va faire un traitement de dix mille lignes puis s’arrêter.
A l’opposé, l’ESB, est conçu pour traiter des faibles volumétries mais en temps réel, donc à haute intensité.
Exemple : le bus va recevoir dix mille données indépendantes les unes des autres au fil de la journée.
Dans ce cas de figure il va faire dix mille traitements d’une ligne, au fil de la journée, et se mettre en écoute après chaque traitement (le flux ESB ne s’arrête jamais).
Complexité
La quatrième différence, liée à la troisième, concerne la complexité.
Dû à la volumétrie, le flux ETL sera plus complexe à mettre en place car le code devra être optimisé afin d’absorber la charge.
Il faut ajouter à cela le processus « T » de « ETL » qui amène à faire plus de transformations.
Une surcouche d’optimisation pour éviter d’altérer les performances du serveur sur lequel le flux sera installé est donc nécessaire.
Cela implique d’écrire la donnée dans des fichiers temporaires, par exemple, pour augmenter le nombre de « sous processus » au sein du flux permettant de découper en plus petites parts le traitement des données.
Le flux ESB quant à lui, ne va récupérer que des données qui sont poussées depuis la source, son but est principalement de faire transiter la donnée pour que les applications soient synchronisées.
La part de transformations au sein d’un flux ESB est plus faible en termes de nombre et en complexité en comparaison de l’ETL.
Ressources machines et parallélisation
La cinquième et dernière différence concerne le nombre de traitements et les ressources consommées en simultanés.
Pour l’ETL les jobs vont s’exécuter un à un et se stopper une fois le traitement terminé.
Ce mode de fonctionnement va donc demander plus de ressources machines pour lancer, initialiser le flux et exécuter les traitements.
Couplée à la volumétrie et au nombre de flux potentiels, la montée en charge du serveur peut être du simple au double (voire plus) si les flux se lancent tous en même temps.
Au contraire de l’ESB qui est en écoute constante, le flux est donc déjà instancié, lancé, les ressources sont prêtes à l’emploi et la donnée reçue arrive selon la charge des applications sources (= les utilisateurs de l’application).
De cette façon plusieurs requêtes peuvent être traitées en même temps sans impacter, autant que l’ETL, les ressources machines.
Comment choisir ? Et devons-nous réellement choisir ?
Avant de déterminer si le besoin est ETL ou ESB il faut se poser les cinq questions suivantes :
- Est-ce que le besoin de mes données est immédiat ?
- Si oui ESB, si non ETL
- Est-ce je dispose de transformations complexes ?
- Si oui ETL, si non ESB
- Est-ce que la volumétrie de mes données est importante ?
- Si oui ETL, si non ESB
- Est-ce qu’à l’avenir je devrais ajouter d’autres applications ?
- Si oui ESB, si non ETL
- Est-ce que je souhaite limiter mon budget ?
- Si oui ETL, si non ESB
« Et si dans tout ça je ne voudrais pas profiter de l’ETL et de l’ESB ? »
La différence entre l’ETL et l’ESB est de plus en plus fine, les intégrateurs couplent ces deux technologies pour avoir les avantages de l’un et de l’autre sans les inconvénients, le tout au sein d’une même plateforme (cf Talend API Cloud Services).
De cette manière, la question n’est plus dans le choix fonctionnel, mais purement technique en fonction du besoin métier, des données reçues, des traitements à effectuer, des contraintes logistiques etc…
C’est donc l’équipe de développement qui devient en charge de ces problématiques, la vision entreprise/dirigeante étant de choisir le bon éditeur d’application (réponse au besoin, scalabilité, maintenabilité et mise à jour) et d’exiger un réceptacle générique pour accueillir chaque évolution au sein de cette plateforme ETL + ESB.
Il ne faut en aucun cas devoir tout refactoriser ou changer l’architecture à chaque ajout d’application. L’expertise technique est donc un élément crucial à prendre en compte si l’on envisage une vision à long terme.
