


¿Qué es un ETL?
ETL (Extract Transform Load), es un middleware que transfiere datos del punto A al punto B a intervalos definidos. Estos tres verbos resumen las tres fases, o procesos, de cada flujo de datos.
La primera fase consiste en extraer los datos, que pueden proceder de cualquier fuente: base de datos, FTP, Amazon S3, Dropbox, Google Drive, carpeta Linux, etc. Dependiendo de la fuente, los datos también pueden extraerse en cualquier formato: SQL, JSON, XML, EDI, posicional, Excel, etc.
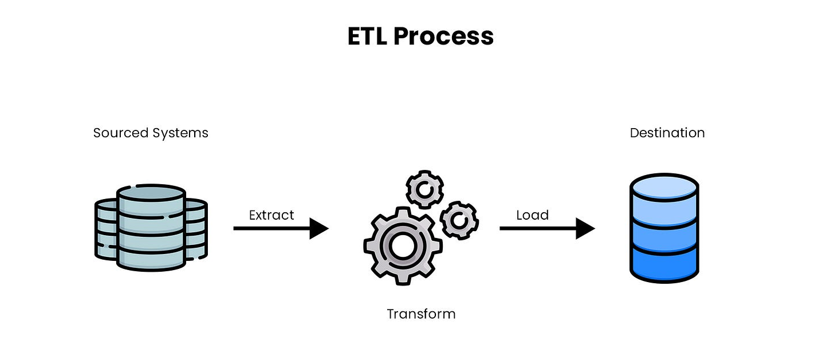
Una segunda fase de transformación aplica las reglas de gestión, limpia los datos, filtra la información irrelevante, etc.
La tercera fase prevé su integración en un destino, del mismo modo que la extracción, en cualquier formato y a partir de cualquier fuente.
La ventaja del ETL es que puede ser flexible y cubrir los casos más comunes gracias a la diversidad de fuentes y formatos de entrada/salida.
El inconveniente del ETL es que puede convertirse en una «caja negra» difícil de mantener o mejorar.
¿Qué es un ESB?
El Bus de Servicios Empresariales (ESB) permite la comunicación entre aplicaciones de un mismo sistema de información que no han sido diseñadas para trabajar juntas.
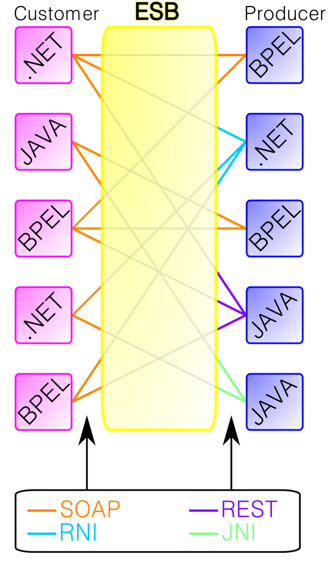
De este modo, si el sistema de información del cliente crece, debido, por ejemplo, a la adquisición de un competidor o a la incorporación de una nueva herramienta para los equipos empresariales, bastará con «conectar» la nueva aplicación al ESB para que se integre en el sistema ya existente.
La ventaja es que no tienes que revisar tu sistema de información cada vez que añades un nuevo software o una nueva aplicación.
El inconveniente es que las aplicaciones deben poder intercambiar información en tiempo real, sobre todo en formato SOAP o REST.
¿Cómo distinguir un ETL de un ESB?
Recuperación de datos
La principal diferencia entre una ETL y una ESB se refiere a la forma en que se recuperan los datos.
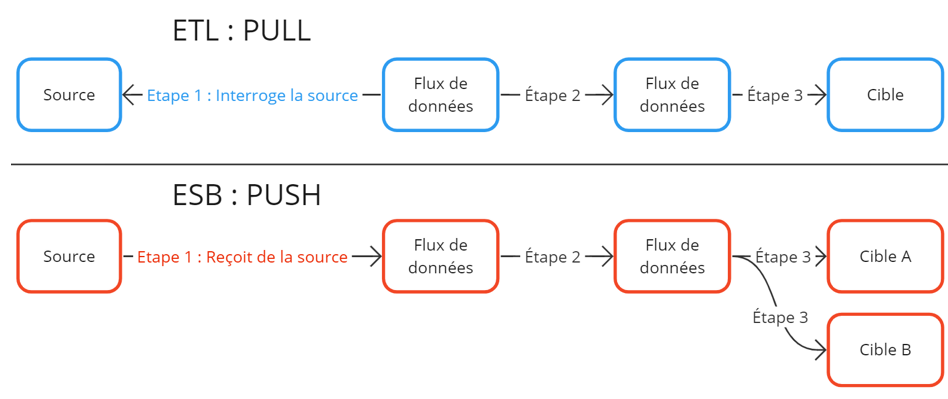
El ETL funciona sobre una base «pull»: el flujo de datos es un flujo programado, que se ejecuta bajo demanda y obtiene (=extrae) los datos de una fuente definida para realizar una función específica.
El flujo ETL es un flujo activo que obtiene datos.
El ESB funciona sobre una base «push»; se dice que el flujo está «impulsado por eventos», y se ejecutará tan pronto como se reciban los datos de una aplicación fuente.
Cuando se reciben los datos, el bus distribuye (=push) la información recibida a las aplicaciones de destino a través de un sistema «publisher/subscriber».
El flujo ESB es un flujo pasivo que transporta los datos.
Tiempo de integración de los datos
La segunda diferencia, vinculada a la primera, es el tiempo de integración de la información.
Como el ETL funciona en modo programado, los datos se integrarán cuando el flujo programado haya terminado su procesamiento. En función del trigger, los datos se sincronizarán al final de la ejecución.
Estos triggers pueden fijarse cada hora, cada día, a intervalos regulares, etc.
El ESB, en cambio, se basa en eventos. Recibirá los datos en el bus en cuanto se creen o modifiquen en la aplicación de origen.
Una vez recibidos en el bus, los datos se envían a los destinos en tiempo real, tras sencillos pasos de transformación y a través de un sistema de «editor/suscriptor».
A diferencia del ETL, la integración tiene lugar en tiempo real.
Volumen
La tercera diferencia, vinculada a la segunda, concierne al volumen.
Los ETL están diseñados para procesar grandes volúmenes de datos en momentos programados del día, y por tanto a baja intensidad.
Por ejemplo, un flujo se lanza una vez al día y lee una tabla con diez mil líneas en la base de datos. En este caso, procesará diez mil líneas y luego se detendrá.
Por el contrario, el ESB está diseñado para procesar bajos volúmenes en tiempo real y, por tanto, a alta intensidad.
Por ejemplo, el bus recibirá diez mil datos independientes a lo largo del día.
En este caso, procesará diez mil líneas a lo largo del día y quedará en modo espera después de cada procesamiento (el flujo del ESB nunca se detiene).
Complejidad
La cuarta diferencia, vinculada a la tercera, concierne a la complejidad.
Debido al gran volumen de datos, el flujo ETL será más complejo de implementar, ya que el código tendrá que optimizarse para absorber la carga.
A esto se añade el proceso «T» de ETL, que requiere más transformaciones.
Por lo tanto, se requiere mayor optimización para no alterar el rendimiento del servidor en el que se instalará el flujo.
Esto implica escribir los datos en archivos temporales, por ejemplo, para aumentar el número de «subprocesos» dentro del flujo, de modo que el procesamiento de datos pueda dividirse en partes más pequeñas.
El flujo ESB, por su parte, sólo recuperará los datos que se envíen desde el origen; su objetivo principal es transferir los datos para que las aplicaciones estén sincronizadas.
El número y la complejidad de las transformaciones dentro de un flujo ESB son menores que en ETL.
Recursos de la máquina y paralelización
La quinta y última diferencia concierne al número de procesos simultáneos y a los recursos consumidos.
Con ETL, los trabajos se ejecutan uno a uno y se detienen una vez finalizado el procesamiento.
Este modo de funcionamiento requerirá por tanto más recursos de la máquina para lanzar, inicializar el flujo y ejecutar los procesos.
Sumado al volumen y al número de flujos potenciales, la carga del servidor puede duplicarse (o incluso más) si los flujos se lanzan todos al mismo tiempo.
A diferencia del ESB, que está constantemente a la escucha, el flujo ya ha sido instanciado y lanzado, los recursos están listos para su uso y los datos recibidos dependen de la carga de las aplicaciones de origen (= los usuarios de la aplicación).
De este modo, se pueden procesar varias solicitudes al mismo tiempo sin que ello afecte a los recursos de la máquina en la misma medida que el ETL.
¿Debemos elegir? ¿Y cómo?
Antes de decidir si necesita ETL o ESB, debe plantearse las cinco preguntas siguientes:
- ¿La necesidad de mis datos es inmediata?
- En caso afirmativo, ESB; en caso negativo, ETL
- ¿Tengo transformaciones complejas?
- En caso afirmativo, ETL; en caso negativo, ESB
- ¿Tengo un gran volumen de datos?
- En caso afirmativo, ETL; en caso negativo, ESB
- ¿Necesitaré añadir otras aplicaciones en el futuro?
- En caso afirmativo, ESB; en caso negativo, ETL
- ¿Quiero limitar mi presupuesto?
- En caso afirmativo, ETL; en caso negativo, ESB
«¿Y si no quiero aprovechar las ventajas de ETL y ESB?«
La línea entre ETL y ESB es cada vez más delgada, y los integradores combinan estas dos tecnologías para obtener las ventajas de ambas sin los inconvenientes, todo ello dentro de la misma plataforma (véase Talend API Cloud Services).
De este modo, la cuestión ya no es de elección funcional, sino puramente técnica, en función de la necesidad de la empresa, los datos recibidos, el procesamiento a realizar, las limitaciones logísticas, etc.
Por tanto, es el equipo de desarrollo el que se convierte en responsable de estas cuestiones,y la empresa/dirección debe elegir el editor de aplicaciones adecuado (respuesta a la necesidad, escalabilidad, mantenibilidad y actualización) y exigir un receptáculo genérico para dar cabida a cada evolución dentro de esta plataforma ETL + ESB.
En ningún caso hay que refactorizarlo todo o cambiar la arquitectura cada vez que se añade una aplicación. El conocimiento técnica es, por tanto, un elemento crucial a tener en cuenta si tienes una visión a largo plazo.
