


By Romain & Pacôme
La centralisation au cœur des systèmes d’information
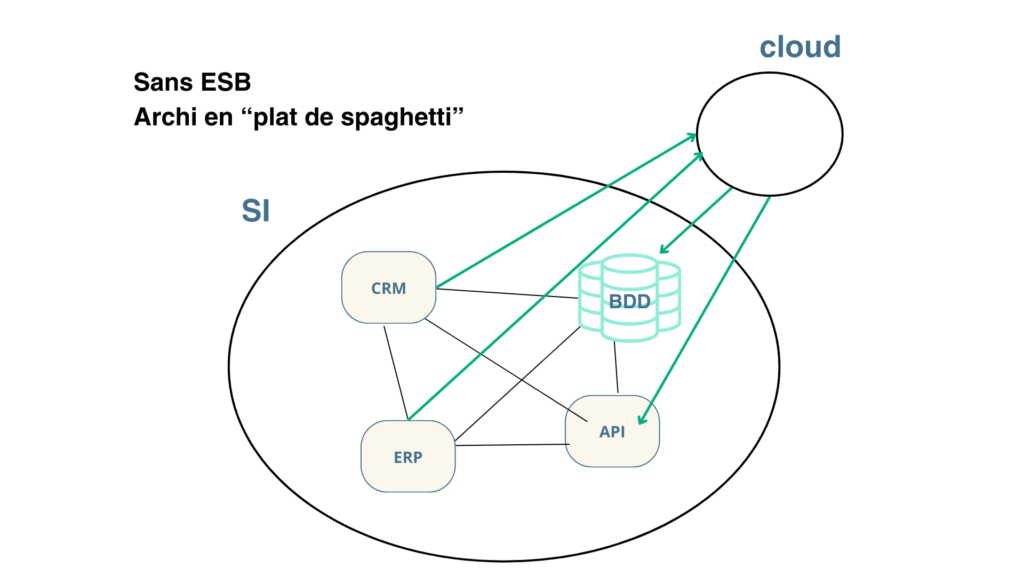
Les entreprises modernes évoluent dans des environnements complexes où les systèmes d’information (SI) sont souvent comparés à un « plat de spaghettis ».
Ce terme décrit une situation où les applications communiquent directement entre elles de manière désordonnée dans une vision macro, créant des problèmes d’interopérabilité, de gestion des données et de visibilité globale.
Le data hub émerge comme une solution centrale à ces problématiques. Il repose sur deux principes fondamentaux : La centralisation des échanges (ESB) et le référentiel de données (MDM).
Uniformisation et centralisation des échanges
Lorsqu’un système d’information n’est pas centralisé, il ressemble à un plat de spaghettis, où chaque application est reliée aux autres par des connexions directes et multiples. Ces interactions complexes augmentent les risques d’erreurs, la difficulté de maintenance et la lenteur des échanges.
Le data hub résout ce problème en centralisant les flux via un ESB (Enterprise Service Bus). Plutôt que de gérer des connexions individuelles entre chaque application, toutes les communications transitent par l’ESB, garantissant que toutes les applications sont interconnectées de manière uniforme et que chaque échange respecte des formats standardisés définis par le pivot.
En centralisant ainsi les échanges :
• Les flux de données deviennent plus faciles à superviser et à maintenir.
• Les nouveaux systèmes peuvent être intégrés plus rapidement, sans affecter les connexions existantes.
• Les performances du SI sont améliorées, car chaque interaction passe par un point unique et optimisé.
Une entreprise qui adopte un data hub avec un ESB peut connecter son CRM, son ERP (et autres applications métiers) et ses bases de données sans avoir à créer des flux spécifiques entre chaque système.
Par exemple, une mise à jour client dans le CRM est automatiquement propagée au système ERP via le data hub, évitant les doublons et garantissant des données uniformes à travers l’organisation.
Ce modèle d’uniformisation et de centralisation renforce la robustesse du SI tout en posant les bases d’une infrastructure évolutive.
Dans la mesure où tout échange doit être centralisé, il faut des outils qui s’adaptent à tout type de techno orientée data. Il est préconisé d’utiliser un ESB ou un ETL, qui permettent de gérer différents types de connexions.
Cette centralisation s’appuie sur les fondamentaux suivants :
Les types de connexions
Deux grandes catégories :
En effet, l’ESB permet de gérer tout type de connexion, que ce soit une base de données, du SFTP, un web service (SOAP ou REST), y compris des technos propriétaires comme Salesforce, Datalake, etc.
En découlent différents types de déclencheurs :
Les échanges dans un data hub se font via deux types de déclencheurs, en fonction des besoins métiers :
• Événementiel, pour aboutir à du temps réel : Une action immédiate déclenche un transfert.
Exemple : Lorsqu’un client passe une commande sur le site e-commerce, celle-ci est immédiatement envoyée au système ERP via le data hub.
Exemples de déclencheurs : CDC, SFTP, web service, fichiers en local…
• Planifié (« schedulé ») : Les transferts se font à intervalles réguliers selon une planification précise interne au data hub.
Exemple : Tous les soirs à minuit, les informations des stocks sont synchronisées entre le WMS (Warehouse Management System) et l’ERP.
Le bus et le pivot : les deux piliers du data hub
Le bus : un tuyau central pour les données
L’ESB (Enterprise Service Bus) est une infrastructure qui connecte toutes les applications à un point central. Les applications peuvent soit envoyer des données, soit se connecter en mode « écoute » pour recevoir les données pertinentes. Il est important de préciser que tout cela se fait autour du bus : l’ESB repose, comme son nom l’indique, sur une structure d’échange de données autour du bus, qui est un tunnel au sein duquel transitent des messages déposés par des services (publish), puis récupérés au fil de l’eau par les services abonnés.
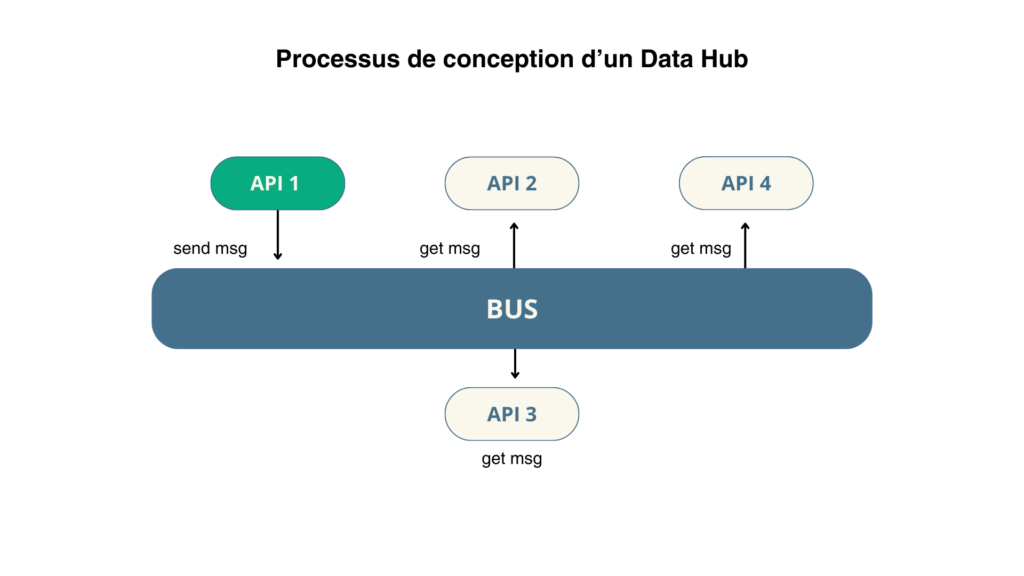
Imaginons une situation où :
- API 1 publie un message spécifique sur le bus de données.
- API 2 et API 3 reçoivent ce message, car elles sont configurées pour l’écouter.
- API 4, quant à elle, est abonnée à un autre type de message et n’est donc pas affectée par celui envoyé par API 1.
Ce fonctionnement montre que chaque service connecté au bus prend uniquement les informations qui lui sont nécessaires, sans interférer avec le fonctionnement global du bus ou des autres services. Cela garantit une communication fluide, optimisée et non intrusive entre les différents systèmes.
Grâce à cette architecture, le bus agit comme un intermédiaire central qui gère les échanges sans surcharge inutile, simplifiant la gestion et la supervision des flux de données.
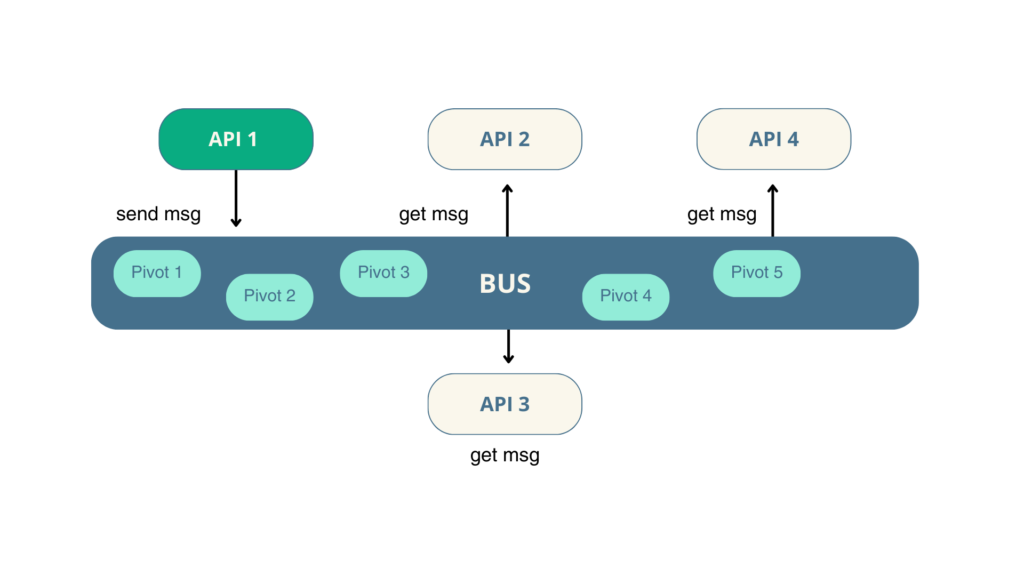
On peut apercevoir l’importance du message qui transite via le bus : ce message, que l’on appelle « pivot », est au cœur du data hub.
Le pivot : un langage commun
Le pivot est au cœur du data hub. Il est la définition « technico-fonctionnelle » d’un seul objet métier.
Il représente le format standardisé des messages échangés entre les applications. Sa définition nécessite une expertise approfondie dès la phase de conception pour éviter tout problème d’interopérabilité.
Exemple : Dans une multinationale, un pivot peut standardiser les données des commandes clients provenant de différents systèmes régionaux, garantissant une structure uniforme pour le reporting global.
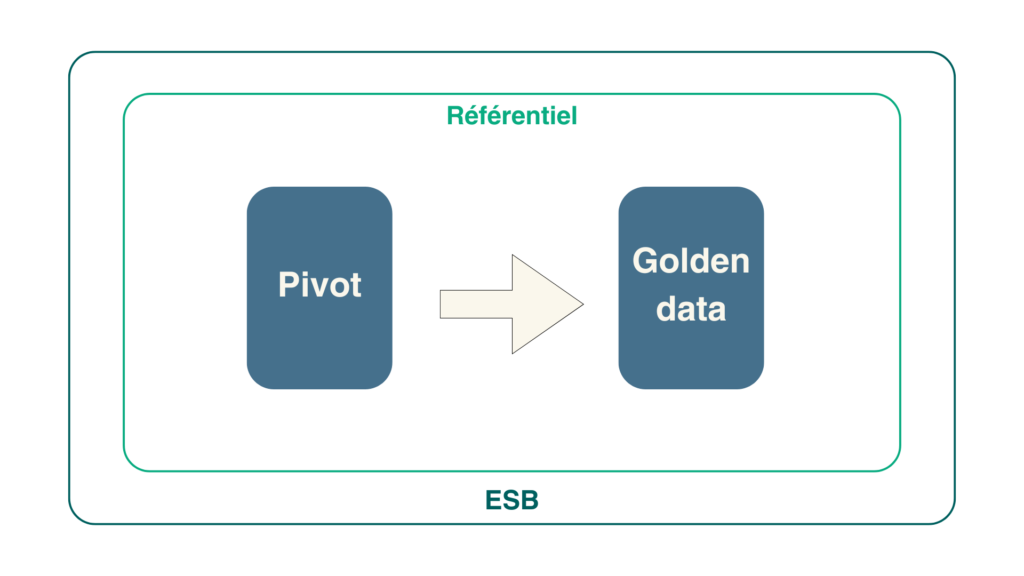
Le pivot est un élément clé pour le data hub, d’où l’importance de la qualité de ses données, ce qui fait appel aux fonctionnalités d’un référentiel.
Le référentiel : gouvernance et enrichissement des données
Un data hub performant repose sur un référentiel robuste, qui joue un rôle central dans la gestion et l’exploitation des données. Ce référentiel garantit :
• La qualité des données (Data Quality) : Les informations collectées sont nettoyées, dédupliquées et harmonisées pour offrir une base fiable et cohérente.
Exemple : Les données clients provenant de plusieurs CRM régionaux sont unifiées pour supprimer les doublons et corriger les incohérences, assurant ainsi une vue globale et précise des clients à l’échelle de l’entreprise.
• La gouvernance des données : Ce référentiel définit des politiques claires sur la gestion des accès, les droits d’utilisation et les responsabilités des utilisateurs.
Exemple : Seuls les responsables RH peuvent mettre à jour les informations des employés, tandis que les responsables financiers peuvent uniquement les consulter, garantissant un contrôle strict des données sensibles.
• L’enrichissement des données : Le référentiel agrège et croise les données issues de multiples systèmes pour les rendre exploitables et stratégiques.
Exemple : Les informations des fournisseurs, provenant de systèmes ERP distincts, sont consolidées pour fournir un tableau complet, permettant des analyses approfondies et une prise de décision éclairée.
Ce référentiel devient ainsi le socle de la fiabilité des flux d’information et un atout stratégique, en aidant les entreprises à tirer le maximum de valeur de leurs données tout en maintenant un contrôle rigoureux.
Le data hub est une approche rationnalisée de l’interopérabilité des applications au sein d’un SI. Cette approche permet d’obtenir les avantages suivants :
Les bénéfices majeurs du data hub
Sécurité renforcée
Le data hub réduit les points d’entrée multiples en centralisant tous les flux au sein de l’ESB. Cela limite les vulnérabilités et renforce la sécurité globale, notamment pour les ouvertures vers l’extérieur (cloud).
Au lieu d’ouvrir plusieurs connexions directes entre les applications internes et les partenaires externes, toutes les données passent par le data hub, qui contrôle et sécurise chaque transaction. De ce fait, il régule les accès de chacun à telle ou telle donnée.
Visibilité accrue
Un data hub centralise l’ensemble des flux de données, offrant une transparence totale sur leur parcours, leur origine et leur destination. Cela permet aux équipes IT de :
• Superviser en temps réel les échanges de données, détecter les anomalies et intervenir rapidement en cas de problème.
• Générer des rapports détaillés et des tableaux de bord pour suivre les performances des flux et mesurer les KPI (indicateurs clés de performance).
Exemple : Un responsable IT peut immédiatement diagnostiquer pourquoi un flux entre un CRM et un ERP a échoué, en identifiant les étapes exactes du problème via le tableau de bord du data hub.
Des alertes automatiques, informant des échecs ou des retards dans les flux, permettent une gestion proactive. Cela améliore la fiabilité globale du système d’information, réduit les interruptions et renforce la confiance des utilisateurs métiers.
Rejeu centralisé
Le système de rejeu intégré au data hub offre une flexibilité unique pour corriger rapidement les erreurs. Lorsqu’un flux échoue, il peut être relancé après résolution du problème, sans nécessiter de développement ou d’intervention manuelle.
Exemple : Si un flux de données entre un ERP et un outil de reporting échoue en raison d’une donnée incorrecte, l’utilisateur peut corriger l’erreur et relancer automatiquement l’échange via le hub.
De plus, le système de rejeu permet d’automatiser (sans intervention) le transfert des messages (pivot) à l’issue de problèmes techniques, tels que des problèmes réseau.
Cette fonctionnalité réduit les délais d’intervention, améliore la résilience des flux et limite les interruptions dans les processus critiques.
Optimisation des coûts
En standardisant les échanges via un pivot unique, le data hub réduit considérablement les efforts de développement et de maintenance. Les entreprises économisent du temps et des ressources en évitant la gestion individuelle des flux pour chaque application.
Exemple : Lors d’une fusion entre deux entreprises, le data hub simplifie l’intégration des systèmes en rationalisant les connexions entre l’ERP central et les nouveaux outils.
Cette standardisation diminue non seulement les coûts opérationnels, mais également les risques d’erreur humaine associés à des flux développés manuellement. Le data hub devient ainsi un levier stratégique pour optimiser le budget alloué aux infrastructures IT.
Du fait de sa complexité et de son envergure, un projet de data hub doit respecter des phases de conception rigoureuses :
Points clés pour réussir un projet data hub
Une phase de conception rigoureuse
Le succès d’un projet de data hub repose sur une planification méticuleuse, qui inclut plusieurs étapes essentielles :
• Identification des besoins métiers : Organiser des ateliers collaboratifs pour analyser les processus existants, identifier les flux critiques et anticiper les besoins spécifiques de chaque département. Ces échanges permettent de s’assurer que le projet répond aux attentes fonctionnelles et stratégiques.
• Définition d’un pivot robuste : Un format standard pour les données doit être établi dès le départ. Ce pivot servira de langage commun, garantissant l’interopérabilité entre les systèmes, comme le CRM, l’ERP ou les outils analytiques.
• Cartographie des flux et interconnexions : Une analyse détaillée des flux actuels et des interactions entre applications est cruciale pour repérer les redondances, les goulots d’étranglement et les opportunités d’optimisation.
Connaissance du SI et maturité fonctionnelle
Cela implique que les équipes internes comprennent non seulement leurs propres besoins, mais également la façon dont leurs processus s’articulent avec le reste du système d’information.
Des ateliers fonctionnels jouent un rôle clé ici, en créant une compréhension commune des objectifs métiers, des dépendances technologiques et des contraintes organisationnelles.
Exemple : Une entreprise qui connaît bien ses flux de données et son écosystème applicatif sera capable de prioriser les intégrations et d’anticiper les éventuels défis.
Mise en place de la solution
Étapes clés pour déployer un data hub performant :
1. Audit préalable
Cette étape vise à analyser en détail l’écosystème actuel. Elle comprend une évaluation des systèmes en place, l’identification des points faibles (duplication de données, silos, etc.) et la collecte des besoins spécifiques.
Objectif commercial : Réduire les coûts d’exploitation en rationalisant les flux et en identifiant les solutions les plus adaptées pour maximiser le retour sur investissement.
2. Proposition de solutions
Après l’audit, des recommandations personnalisées sont formulées. Celles-ci incluent des options techniques détaillées, une estimation des coûts et des délais, ainsi qu’une évaluation des risques.
Approche commerciale : Mettre en avant des solutions flexibles et évolutives, capables de s’adapter aux besoins actuels tout en anticipant les évolutions futures de l’entreprise.
3. Proof of Concept (PoC)
Un PoC permet de tester la faisabilité technique et fonctionnelle des solutions proposées dans un environnement contrôlé. Cela réduit les incertitudes avant un déploiement complet.
Perspective commerciale : Démontrer rapidement la valeur ajoutée du projet pour sécuriser l’adhésion des parties prenantes.
4. Accompagnement par des experts
Un suivi rigoureux tout au long du projet est essentiel pour garantir une implémentation réussie. Cela inclut une documentation claire, des formations pour les équipes internes et un support post-déploiement.
data-major se positionne comme un partenaire stratégique, capable d’offrir un accompagnement sur mesure, en s’appuyant sur une méthodologie éprouvée et des retours d’expérience concrets.
Une architecture incontournable pour un SI moderne
Le data hub ne se limite pas à une solution technologique : c’est un véritable outil stratégique. En centralisant les flux, en uniformisant les données et en garantissant une interopérabilité totale, il offre aux entreprises un atout essentiel pour gagner en performance, en sécurité et en visibilité.
Encore plus loin ? Sa robustesse et sa flexibilité lui permettent de gérer efficacement des situations généralement complexes, telles que la fusion des SI à la suite d’un rachat ou d’une fusion au sein d’un groupe.
Fusion de SI
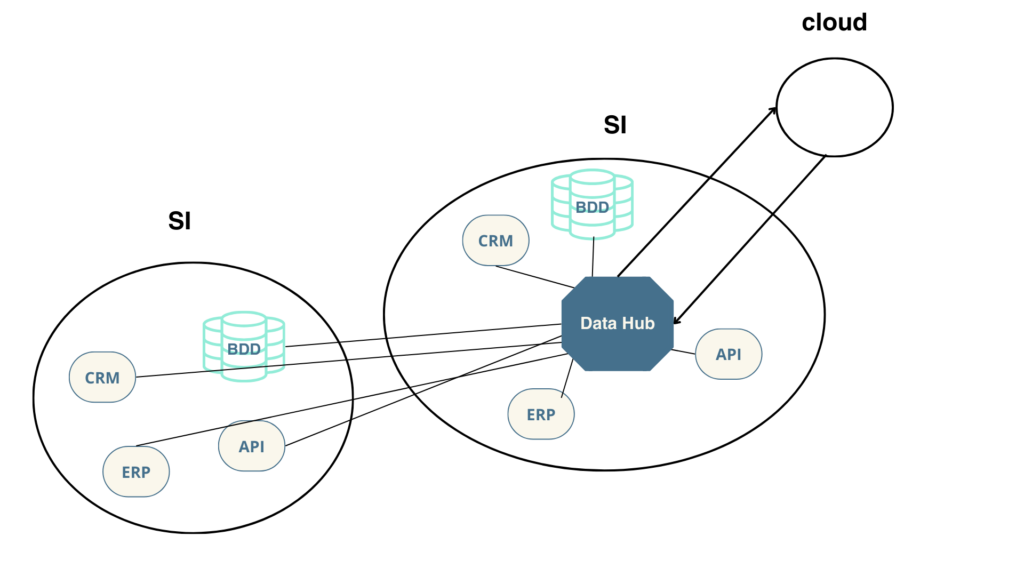
En effet, lors d’une fusion des SI, il est normalement de rigueur de développer les connexions entre chaque application. Or, dans cette architecture centralisée, il suffit tout simplement de développer les demi-interfaces pour se connecter au data hub.
Prêt à franchir le cap ? Lancez votre transformation dès aujourd’hui pour un système d’information durable et efficace !
N’hésitez pas à découvrir notre précédent article « Tendances Data 2025 : top 5 des prédictions du marché », où nous abordons nos prédictions pour cette année !
