


Introduction : un peu d’histoire
Le terme « intelligence artificielle » (IA) a été formulé pour la première fois en 1956 pendant une conférence fondatrice qui a posé les bases de cette discipline. Toutefois, les premières tentatives pour imiter le fonctionnement du cerveau humain remontent à 1943, lorsque McCulloch et Pitts ont modélisé un neurone à l’aide d’opérations logiques. Ce travail théorique a jeté les bases de ce que l’on appelle aujourd’hui le deep learning.
Les premiers chatbots et l’illusion de l’intelligence
Dans les années 60, le programme ELIZA, conçu pour simuler un dialogue humain, marquait une étape importante. En repérant des mots-clés et en répondant par reformulation, ELIZA donnait l’illusion d’une conversation cohérente. Mais ce n’est qu’avec les modèles modernes comme ChatGPT que les machines ont commencé à comprendre le contexte et à interagir de manière fluide.
L’IA dans les jeux : de Deep Blue à AlphaGo
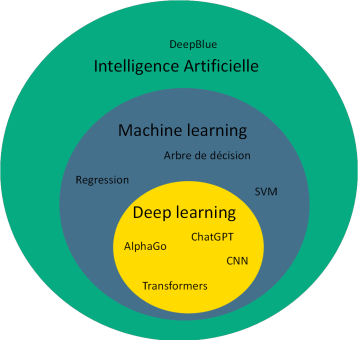
Dès les années 80, les jeux vidéo ont intégré des comportements d’IA rudimentaires basés sur des règles simples (« si le joueur s’approche, alors attaque »). En 1997, Deep Blue (IBM) bat le champion d’échecs Garry Kasparov grâce à une analyse massive de coups possibles, sans apprentissage. En revanche, en 2016, AlphaGo (DeepMind) révolutionne le domaine en battant le champion de go Lee Sedol. AlphaGo utilise le deep learning et l’apprentissage par renforcement, simulant des millions de parties pour affiner sa stratégie.
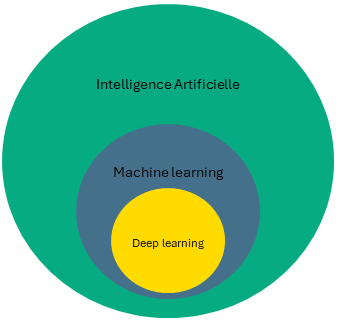
Faire la différence entre IA, machine learning et deep learning
L’intelligence artificielle est un domaine large. Elle comprend :
- Des systèmes à règles fixes (comme Deep Blue)
- Des systèmes apprenants, via le machine learning
- Une branche plus avancée : le deep learning
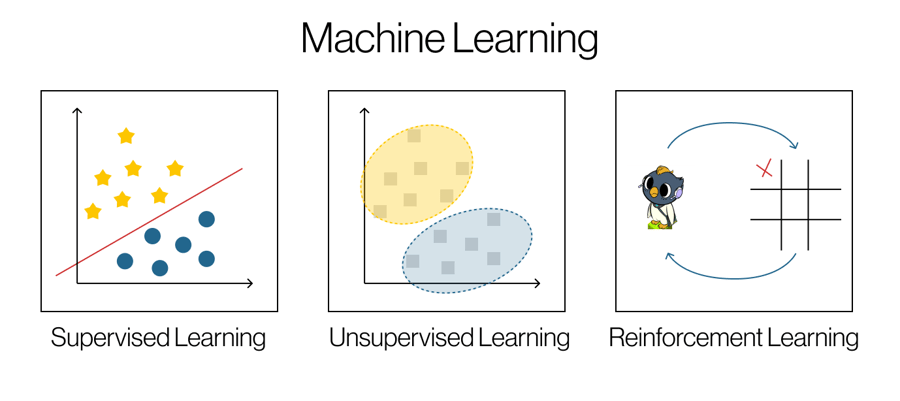
Les quatre grands types d’apprentissage en machine learning :
- Apprentissage supervisé : à partir de données annotées.
- Apprentissage non supervisé : l’algorithme cherche seul des structures.
- Apprentissage auto-supervisé : apprentissage sur des données partiellement masquées.
- Apprentissage par renforcement : l’IA apprend par essai-erreur en maximisant les récompenses.
Un bon modèle d’IA repose sur des données de qualité et une phase d’entraînement rigoureuse.
Machine learning : des modèles adaptatifs
Le machine learning (apprentissage automatique) permet à un système d’établir des prédictions à partir de données. Il repose sur des modèles comme :
- Arbres de décision : un des cas d’usage les plus courants est l’évaluation du risque de crédit.
- SVM (Support Vector Machines) : souvent utilisés pour des applications de reconnaissance faciale.
- Random Forests : très efficaces pour des cas d’usage tels que la recommandation de contenu (ex. : Netflix).
Ces méthodes exigent souvent une extraction manuelle de caractéristiques pertinentes par les data scientists.
Deep learning : l’évolution vers l’autonomie
Le deep learning s’appuie sur des réseaux de neurones profonds. Ceux-ci extraient automatiquement les bonnes caractéristiques à partir de données brutes. C’est ce qui permet de traiter des images, sons ou textes sans intervention humaine.
Exemples :
CNN (Convolutional Neural Networks) : utilisés notamment pour des cas de reconnaissance d’image (ex. : détection d’objets, classification d’images).
Transformers : au cœur des applications de traitement du langage naturel telles que ChatGPT ou la traduction automatique.
Deep learning vs Machine learning, comprendre la différence avec un exemple : reconnaître un chat dans une image
- Machine learning classique : l’humain doit définir à l’avance les traits à repérer (forme des oreilles, couleurs, etc.)
- Deep learning : le réseau apprend à identifier automatiquement les caractéristiques visuelles pertinentes, sans intervention humaine
Une synthèse visuelle pour se repérer dans l’univers des IA
Impact environnemental de l’IA
L’intelligence artificielle moderne, avec ses modèles géants comme GPT-4 ou Gemini, consomme une énergie colossale. L’entraînement de ces modèles mobilise des centaines de serveurs pendant des semaines, résultat : une consommation énergétique très élevée et des coûts de calcul importants.
Heureusement, des efforts sont menés pour rendre ces systèmes plus sobres et plus durables. Une IA responsable passe aussi par une meilleure efficacité énergétique.
Une boîte noire à décoder
L’intelligence artificielle n’est pas magique. C’est un ensemble d’approches techniques qu’on peut comprendre, maîtriser et questionner. En comprenant les différences entre algorithmes prédéfinis et algorithmes apprenants, on peut adopter un regard plus critique sur les résultats produits par ces systèmes.
🎯 Envie de tirer pleinement parti de vos données ?
Si vous souhaitez aller plus loin sur le sujet :
- Livre : Deep Learning de Ian Goodfellow
- Bibliothèques Python : scikit-learn, TensorFlow, PyTorch
