

Dans un monde où les organisations manipulent une multitude de systèmes, d’applications et de sources, la capacité à extraire, transformer et charger (ETL) les données demeurent un enjeu crucial.
Bien que de nouvelles approches comme l’ELT, les architectures orientées API ou le streaming en temps réel se développent, l’ETL conserve une place incontournable dans de nombreux projets data.
Alors, quel est aujourd’hui son rôle ? Et dans quels contextes reste-t-il un outil clé ?
L’ETL, un processus toujours d’actualité
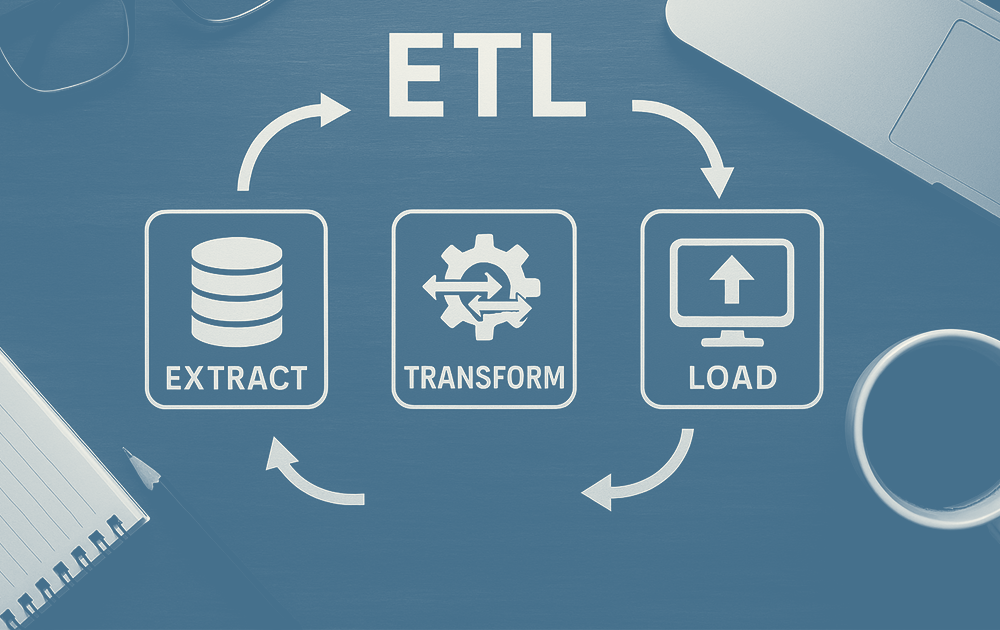
L’ETL vise à transformer des données brutes et hétérogènes en informations prêtes à être exploitées :

- Extract (extraire) : collecte des données issues de multiples sources (bases relationnelles, ERP, CRM, API, fichiers plats, capteurs, etc.).
- Transform (transformer) : nettoyage, harmonisation, enrichissement ou calculs spécifiques pour les rendre cohérentes.
- Load (charger) : alimentation d’entrepôts de données, de data marts, ou de systèmes analytiques.
Ce processus, historiquement central dans la Business Intelligence, reste fondamental lorsqu’il s’agit de garantir la fiabilité et la pertinence des données destinées aux analyses ou aux reportings stratégiques. le rôle d’un orchestrateur invisible, préparant la donnée brute pour en faire un véritable actif stratégique.
Un rôle clé dans la qualité et la gouvernance
Un MDM efficace repose sur la qualité des données intéDans un contexte de Master Data Management (MDM), l’ETL joue un rôle important mais bien délimité : il intervient en amont, en alimentant la solution MDM avec les données sources issues des différents systèmes de l’organisation. Ces données, souvent hétérogènes, sont extraites et transférées par l’ETL, mais ce n’est pas lui qui en assure la qualité ni la gouvernance.
C’est au sein même du MDM que ces données sont ensuite nettoyées, harmonisées, enrichies, validées, puis gouvernées selon des règles métiers précises. L’ETL ne fait donc qu’apporter la matière première : il n’est ni garant de la qualité finale, ni responsable des référentiels eux-mêmes.
En pratique, l’ETL n’est donc pas le garant d’un MDM, mais il joue un rôle de facilitateur en amont ou en parallèle, selon les architectures.
Cas d’usage par secteur
- Retail & e-commerce : consolider des données produits issues de multiples catalogues et marketplaces pour alimenter des dashboards de suivi.
- Finance : intégrer des données de transactions depuis différents systèmes pour des analyses réglementaires ou de risques.
- Industrie & IoT : agréger les flux de capteurs pour alimenter des tableaux de bord opérationnels.
Ces cas montrent que l’ETL reste précieux dans tout contexte où la donnée doit être consolidée, fiabilisée et historisée.
Vers une approche hybride : ETL, ELT et API
Aujourd’hui, les architectures data modernes reposent rarement sur l’ETL seul. Elles combinent :
- ETL : utile pour les transformations complexes et les traitements batch.
- ELT : privilégié dans les environnements cloud, où la puissance de calcul des data warehouses modernes (Snowflake, BigQuery, Databricks) prend le relais.
- API & streaming : adaptés aux intégrations en temps réel et aux besoins de synchronisation instantanée.
L’enjeu n’est plus de choisir un outil unique, mais de construire une chaîne d’intégration adaptée aux besoins métier et aux usages data.
Conclusion : un outil historique qui se réinvente
L’ETL n’est peut-être plus le seul standard des projets d’intégration, mais il reste un maillon essentiel dans de nombreux cas d’usage.
En l’articulant avec d’autres approches modernes (ELT, API, MDM, orchestration cloud), il continue de jouer son rôle de garant de la fiabilité des données et constitue un processus indissociable des systèmes décisionnels.
Vous vous interrogez sur l’architecture d’intégration la plus adaptée à vos besoins ?
Nos experts peuvent vous aider à choisir et mettre en œuvre la bonne combinaison d’outils pour sécuriser et valoriser vos données.
